Kontext
Ich habe ein neues Sprachmodell von Grund auf mit dem Huggingface-Frameworkes und einem vorkonfiguriertem Roberta-Modells auf einem eigenen Datensatz trainiert. Nun wollt ich einen neuen Datensatz mit Hilfe des trainierten Modells vektorisieren.
Beobachtung
Es trat ein Fehler auf:
RuntimeError the expanded size of the tensor (100) must match the existing size (64) at non singleton dimension 1.
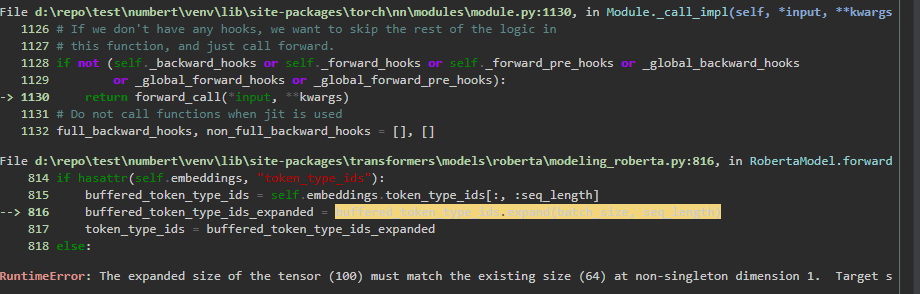
Auflösung des Problems
Dieser Fehler tritt auf, weil das trainierte Sprachmodell eine maximale Dokumentlänge von 64 verwendet hat. Der neue Datensatz, den ich zu vektorisieren versuchte, hatte jedoch eine maximale Dokumentenlänge von 100. Der Grund liegt in der Tokenisierung des Datensatzes, wo ich fälschlicherweise die max_length auf 100 gesetzt und ein entsprechendes max_length padding konfiguriert habe. Dadurch hat der Eingabevektor jetzt nicht die gleiche Dimensionalität wie die Embeddings, die zuvor zum Trainieren des Sprachmodells verwendet wurde, was zu dem oben erwähnten Fehler führt.