
Recently, we upgraded our Airflow setup from version 2 to 3, as AF2 is approaching end-of-life.
The code migration itself worked mostly fine. However, with Airflow 3’s new architecture, we observed significant performance drops and occasional downtime of the dag processor and api server.
Besides general AF3 issues with the metadata database (as described in this medium post), one of our DAG generation scripts showed excessive parsing times. This post summarizes our optimization journey.
General context
In Airflow 3, most metadata queries are handled via the API, including access to Variables and Connections.
Current state of our script
We use a script to dynamically generate DAGs. In total, we have ~700 DAGs, of which ~650 are generated this way.
The script works roughly as follows:
- Load shared metadata
Retrieve required data from the database. - Build ETL configuration objects
Create a list of ETL configuration objects, each representing one job. - Iterate over all configurations
Generate DAGs dynamically.- 3.1 Initialize setup
Validate configuration and derive attributes. - 3.2 Construct DAG and tasks
- Create the DAG instance
- Initialize a resource manager per job
- Build task structures depending on job type
- 3.1 Initialize setup
We already applied some general optimizations:
- Cache database queries to avoid repeated access (step 1)
- Use
AirflowParsingContextand lazy initialization to avoid unnecessary work during task execution (step 3.1, see https://hungsblog.com/en/technology/troubleshooting/airflow-fill-dagbag-takes-too-long/)
These improvements mainly reduce overhead during task execution, not DAG parsing itself.
Method: DAG parsing optimization
The following optimizations target the DAG construction phase. Measured parsing times were done on step 3.2, so there is a slight overhead from step 1 to add to the total parsing time.
Optimization steps
The following optimizations were introduced sequentially.
- Raw (non working)
Without caching database queries, the script does not complete. With 600+ DAGs, even short query times accumulate and hit dag parse timeouts. - Noopt (baseline)
Unoptimized version. Variables, connections, and derived properties are resolved during parsing. - Novar
Lazy-load Variables and move the calculations to task execution instead of during DAG parsing.
Each job type had ~1–2Variable.getcalls. - Nocalc
Removed property calculations (e.g., file reads, dataframe filtering). These were based on cached data but still added overhead. - Nocon
The resource manager was instantiated per DAG configuration and fetched connection data via API calls (though not all job types required it). We refactored it to be able to cache and reuse the retrieved data. - Novar2
Removed additionalVariable.getcalls in a specific job type (104 instances). - Redcon (global optimization)
Introduced a singleton connection factory.
Instead of callingBaseHook.get_connectionin each loop for job-specific properties, we cache Airflow connection objects after the first retrieval to reduce repeated API calls.
Results
Each optimization step was executed three times and averaged. The results below show the reduction in parsing time for step 3.2 of the DAG generation process.
| optimization_step | avg_parse_time in s | |
| 0 | noopt | 46.726 |
| 1 | novar | 19.560 |
| 2 | nocalc | 19.031 |
| 3 | nocon | 7.452 |
| 4 | novar2 | 2.430 |
Below is a boxplot showing the parsing time per DAG, averaged across the three runs. The Redcon optimization did not affect per-DAG parsing time, but reduced the overall script parsing time by 20 seconds (mainly in step 2).
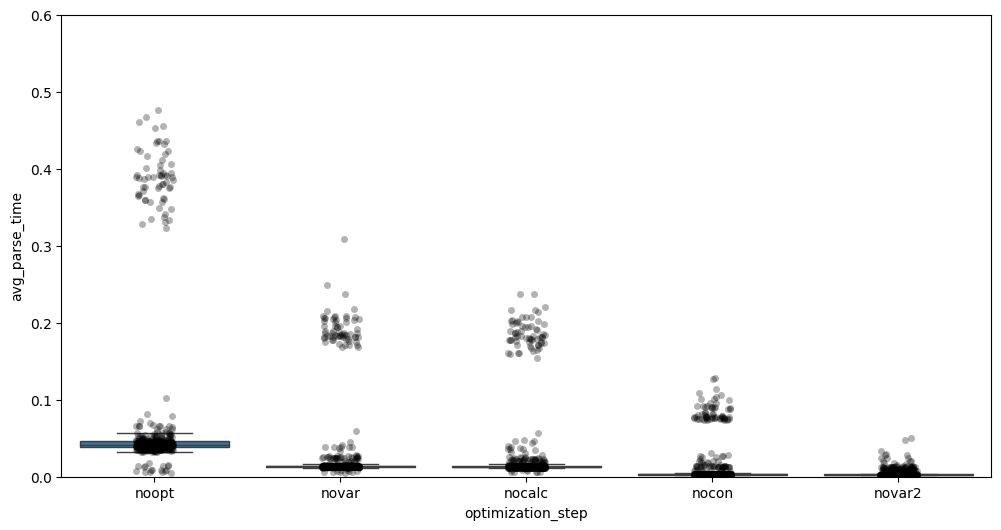
- NOOPT: We can see that the baseline contains several DAGs with significantly longer parsing times, likely belonging to the same job type.
- NOVAR: Reducing variable related calls already leads to a noticeable improvement in parsing time.
- NOCALC: In contrast, removing additional calculations and function calls has little to no impact.
- NOCON: Reducing connection-related API calls results in another clear drop in parsing time.
- NOVAR2: Finally, after further reducing Variable calls for a specific job type, the parsing times become much more uniform, with nearly all DAGs parsing at a similar speed.
Discussion
The real performance bottleneck during dag parsing is API calls. While this is not surprising (even mentioned in the Airflow optimization guide, see best-pratices) the impact becomes significant at scale. Each call introduces only small overhead, but it quickly adds up when many DAGs are created over time. Therefore, API calls should be avoided during DAG generation and instead moved to task execution, for example into Operators.
This effect is further amplified if AirflowParsingContext is not used to limit parsing to only the necessary information during task execution. In that case, each task execution triggers the full script, including all API calls, effectively DOSing your own API server.
While the REDCON optimization step did not impact per-DAG parsing time as meassured above, it significantly reduced overall parsing time. With over 600 DAGs but only ~40 unique connection_ids, repeated API calls added up quickly. By caching these connections after the first retrieval, we avoid hundreds of redundant API calls, resulting in a substantial time saving. This highlights the importance of caching shared metadata such as connections whenever possible.
Additionally, more dynamically changing jobs likely lead to frequent changes in DAG definitions. With Airflow 3’s DAG versioning, this can result in an excessive number of DAG versions (see this Git issue).