TLDR: np.nan objects are of type float
Observation
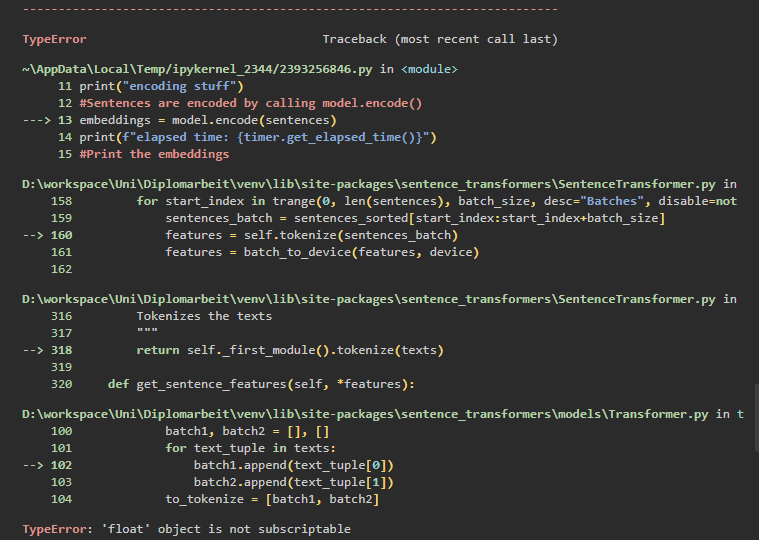
I was trying to apply the SentenceTransformer (v2.2.0) on a list of custom documents to create embeddings for each of them, however i would get the error “TypeError: ‘float’ object is not subscriptable“. The traceback refered to the tokenize function, so let’s have a closer look.
Explanation
The input variable of said function is assumed to be a list. The function would check the first element of the list, whether it would be a string or a dictionary. In any other case it apparently assumes a tuple. In my case i read a csv file into a dataframe and created a list of strings out of this dataframe. However i did not realize, that empty strings were converted to np.nan objects which are of type float. Coincidentally, the batch size was configured in such a way that every other batch, the first element of the list would be the np.nan object and thus neither a string nor a dict. Consequently the function assumes a list of tuples and tries to get the first and second element. However a ‘float’ object is not subscriptable ;).
Resolution
Just replace the np.nan’s with an empty string and the function will recognize the right datatype and if condition.
df = df.fillna('')