Context
I trained a new languagemodel from scratch using huggingface’ framework and a preconfiguration of Roberta Model on a custom dataset. Now i wanted to vectorize a new dataset using the pretrained model.
Observation
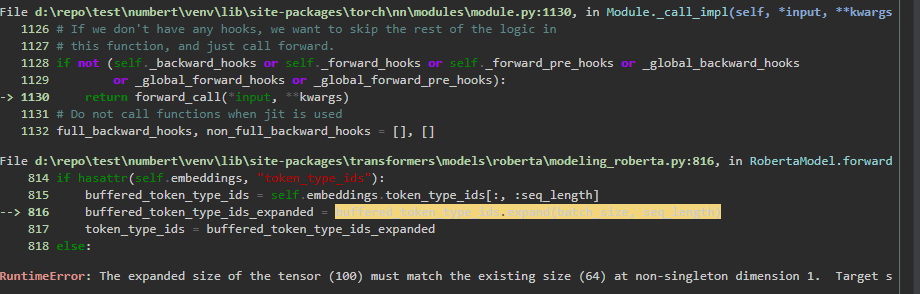
I receive an error:
RuntimeError the expanded size of the tensor (100) must match the existing size (64) at non singleton dimension 1.
Resolution
This error appears, because the languagemodel trained utilized a maximum document length of 64. However the new dataset, which I tried to vectorize had a maximum document length of 100. The reason lies in the tokenization process of the dataset , where i mistakenly set the max_length to 100 and configured a max_length padding. Thus, the input vector now has not the same dimension as the embedding previously used to train the languagemode resulting in the aforementioned error.