TLDR: np.nan Objekte sind fom Typ float
Beobachtung
Um numerische Repräsentationen für Dokumente (sogenannte Embeddings) zu erstellen habe ich mich dem SentenceTransformer (v2.2.0) bedient, allerdings wurde in vereinzelten Fällen der Fehler “TypeError: ‘float’ object is not subscriptable” geworfen. Der traceback bezieht sich auf die tokenizer Funktion, die wir uns hier etwas genauer anschauen wollen:
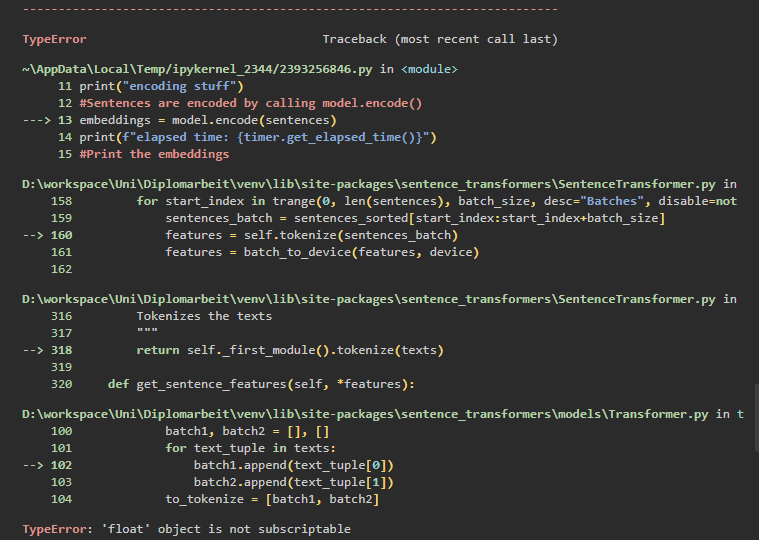
Als Eingabevariable dieser Funktion wird eine Liste erwartet. Die Funktion würde das erste Element nehmen und überprüfen, ob es sich um einen String oder ein Dicitonary handelt. In allen anderen Fällen geht es von einem Tupel aus. In meinem Szenario habe ich eine csv Datei in ein dataframe eingelesen und daraus eine Liste von Elementen erstellt, wo jedes Element ein Dokument repräsentiert. Allerdings war mir nicht bewusst, dass die csv auch leere Felder beinhaltete, sodass diese leeres Strings in np.nan-Objekte vom Typ Float konvertiert wurden. Zufällig war die Batchgröße der Transformation auch so konfiguriert, dass sie nur ab und zu auf eine Liste treffen würde, bei dem das erste Element solch ein leerer String / float Objekt war. Folglich geht die Funktion von einer Liste von Tupeln aus und versucht, das erste und zweite Element zu erhalten. Allerdings lässt sich ein “float” Objekt nicht indexieren :).
Lösung
Es müssen im dataframe nur die np.nan Felder mit leeren Strings ersetzt werden, damit die Funktion den richtigen Datentypen erkennt.
df = df.fillna('')