Warum ändert sich bei einer Änderung der Anzahl der Heads eines Transformermodell nicht dessen Anzahl an Parametern? – Das war die Frage, die ich mir gestellt habe. Nachdem ich die entsprechende Matrizenmultiplikation nachvollzogen und zu einem entsprechendem Ergebnis gekommen bin, möchte ich dieses Wissen weitergeben und versuchen, den Multi Head Attention (MHA) Mechanismus an einem kleinen Beispiel visuell zu erklären. Bitte beachten, dass ich in diesem Beitrag nur auf den MHA-Mechanismus eingehenwerde, da es bereits hervorragende Erklärungen zum Transformer-Modell gibt, wie zum Beispiel die von Jay Alammar (The Illustrated Transformer)
Beobachtung: Eine Änderung der Anzahl der Heads führt nicht zu einer Änderung der Anzahl der Parameter in einem Transformermodell
from transformers import RobertaForMaskedLM, RobertaConfig
config_3 = RobertaConfig( num_attention_heads=4)
config_12 = RobertaConfig(num_attention_heads=12)
model_head3 = RobertaForMaskedLM(config=config_3)
model_head12 = RobertaForMaskedLM(config=config_12)
print(f"Number of parameters with 3 heads:{sum(p.numel() for p in model_head3.parameters() if p.requires_grad)}")
print(f"Number of parameters with 12 heads:{sum(p.numel() for p in model_head12.parameters() if p.requires_grad)}")
# output:
# Number of parameters with 3 heads:109514298
# Number of parameters with 12 heads:109514298Mir ist aufgefallen, dass bei Änderung der Anzahl der Heads in einem Robertamodell, die Anzahl der Parameter im Modell aber gleich geblieben ist. Warum ist das so?
Detaillierte visuelle Erklärung des Multi Head Attention Mechanismus
Im folgenden Abschnitt werden wir uns nur auf den Teil “Multi Head Attention” des Artikels “Attention Is All You Need” von Vaswani et al. (2017) konzentrieren. Für den Einstieg in dieses Thema werde ich mich den Illustrationen von Jay Alammar bedienen.
Self Attention
Der Inputembedding (X) wirdmit Gewichtsmatrizen WQ. WK, WV multipliziert, um die Queries (Q), Keies (K) und Values (V) zu erzeugen. Anschließend werden diese Matrizen Q, K und V miteinander “verrechnet”, um die Self Attention Matrix (Z) zu erhalten.
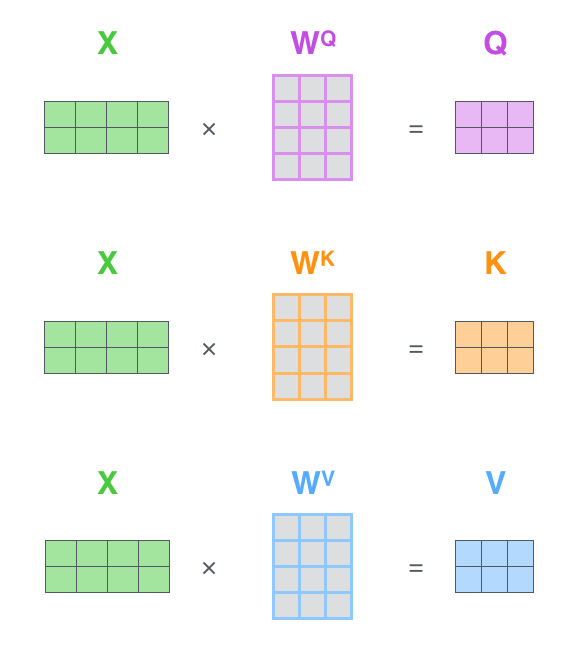
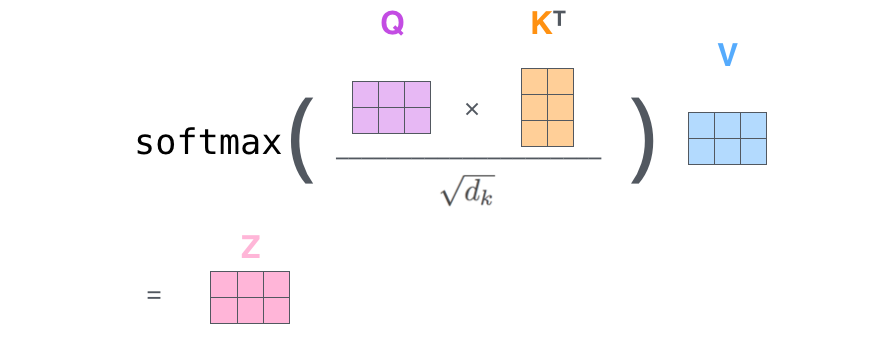
Multi-Head
“Instead of performing a single attention function with d_model-dimensional keys, values and queries, we found it beneficial to linearly project the queries, keys and values h times with different, learned linear projections to d_k, d_k and d_v dimensions, respectively.” (Vaswani et al, 2017, p.4)
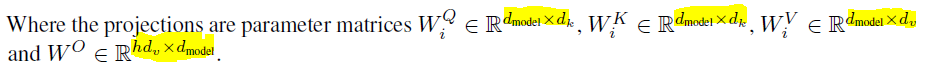
Das bedeutet, dass der Inputembedding X nicht nur einmal mit den Gewichtsmatrizen WQ, WK, WV multipliziert wird, um Q, K und V zu erzeugen, sondern mit h verschiedenen Gewichtsmatrizen WQ_i, WK_i, WV_i. Die Parameter sind im Folgenden aufgeführt:
- h : Anzahl der Heads
- d_model : Dimensionalität des Embeddingvektors
- d_k : Dimensionalität der Query und Key Vektoren
- d_v: Dimensionalität der Value Vektoren, theorthisch könnte d_v unterschiedlich zu d_k sein
- d_k = d_v = d_model/h
Die folgende Abbildung soll etwas Licht ins Dunkel bringen, indem sie eine lineare Projektion einer Einbettung mit unterschiedlicher Anzahl von Heads simuliert. Hier ist zu beachten, dass sich mit der Anzahl der Heads auch die d_k und d_v ändern und damit die Dimensionalität der Gewichtsmatrizen. Dies ist auch der Grund, warum die Dimension der Einbettungen ein Vielfaches der Anzahl der Köpfe sein muss – weil Mathe 🙂
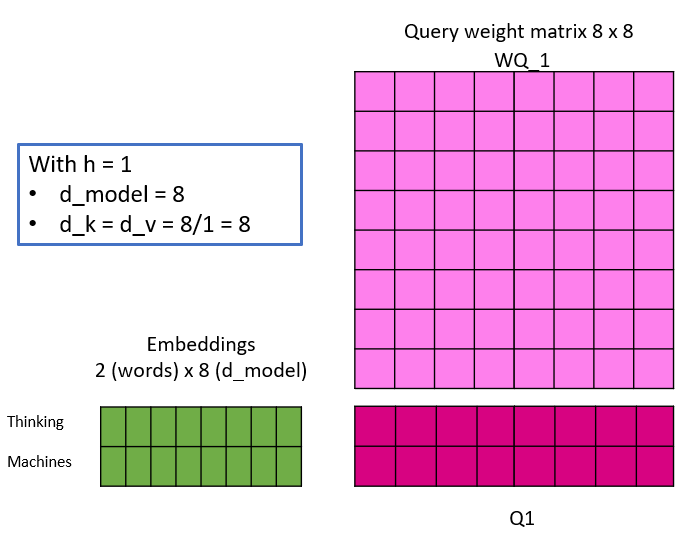
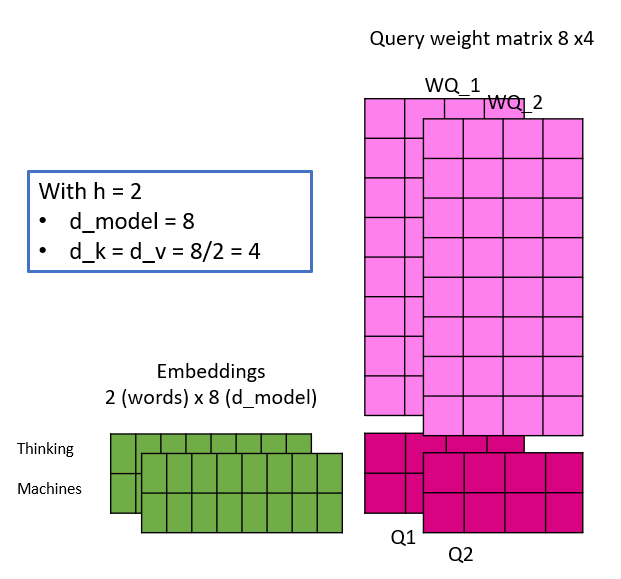
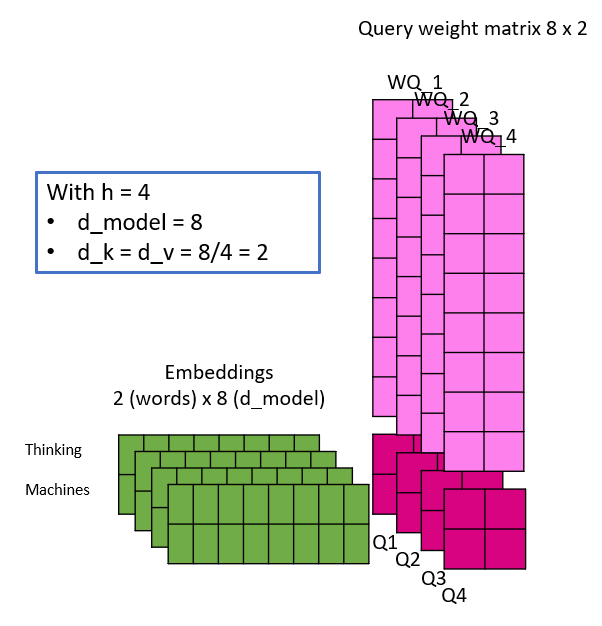
Die Keys, Queries und Values werden wie dargestellt kalkuliert und die Self Attention Matrix Z wird dann für jeden Head parallel berechnet. Wie ursprünglich beobachtet, ist nun visuell erkennbar, dass sich bei einer Änderung der Anzahl der Köpfe die Anzahl der Gewichtungsparameter nicht ändert.
Für mich war es wichtig zu verstehen, dass, obwohl sich die Anzahl der Heads ändert, der Inputembedding nicht aufgeteilt, sondern vielmehr kopiert und jede dieser Kopien mit verschiedenen Gewichtsmatrizen (Heads) multipliziert wird, um die jeweiligen Queries, Keys und Values zu berechnen.
“Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions” (Vaswani et al., 2017, p.5)
Jeder Head ist für die vollständige Berechnung der Selfattention für den gesamten Inputembedding verantwortlich, nicht nur für eine Teilmenge davon, und erstellt h Attention Matrizen. Diese Matrizen ermöglichen die Berücksichtigung von Informationen aus verschiedenen Blickwinkeln. Ich erinnere mich, einen interessanten Kommentar gelesen zu haben, der die Bemerkung gemacht hat, dass diese Matrizen mit den feature maps bei der Objekterkennung verglichen werden können, die ebenfalls nur auf ein bestimmtes Informationsmuster achten.
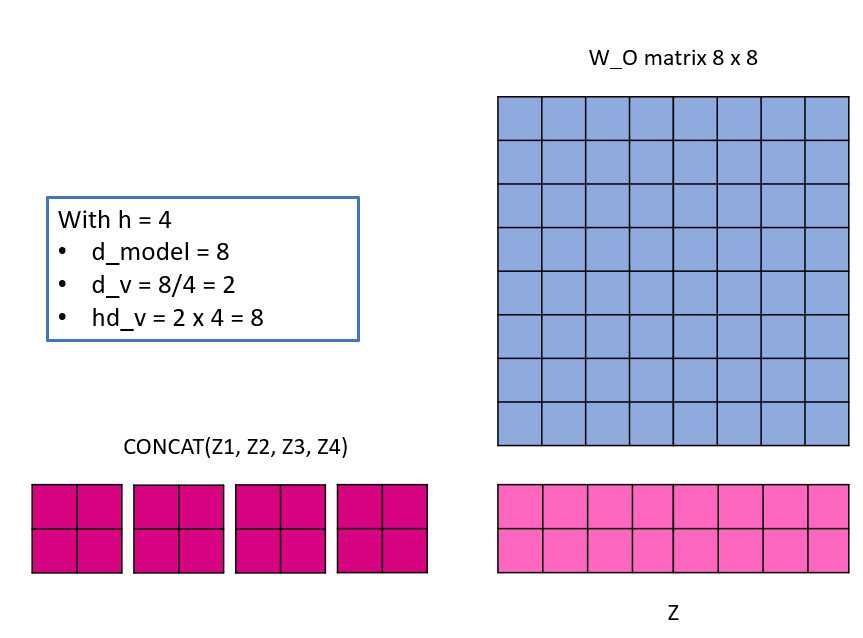
Da eine einzige Matrix für die nächste Schicht erwartet wird, müssen die h Self Attention Matrizen nun zusammengefügt werden. Dazu werden sie konkatiniert und dann ein letztes Mal mit einer Gewichtsmatrix W_O mit den Abmessungen hd_v x d_model multipliziert.
Referenzen
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. ArXiv:1706.03762 [Cs]. http://arxiv.org/abs/1706.03762
Weiterführende Quellen
BERT Research – Ep. 6 – Inner Workings III – Multi-Headed Attention, ein sehr aufschlussreiches Video, welches auch auf Jay Alammars Beitrag eingeht, aber etwas zu kurz die Auswirkungen einer Änderung der Anzahl der Heads erläutert.
How to account for the no:of parameters in the Multihead self-Attention layer of BERT – stackexchange, Dileep Kumar Patchigolla erklärt, wie er die Anzahl der Gewichtsparameter in Bezug auf die Multi Head Attention berechnet hat