
Kürzlich haben wir unser Airflow-Setup von Version 2 auf 3 aktualisiert, da AF2 sich dem End-of-Life nähert. Die Code-Migration selbst verlief größtenteils problemlos. Mit der neuen Architektur von Airflow 3 beobachteten wir jedoch deutliche Performance-Einbußen sowie gelegentliche Ausfälle des DAG-Prozessors und des API-Servers.
Neben allgemeinen Problemen von AF3 mit der Metadaten-Datenbank (wie in diesem Medium-Post beschrieben) zeigte eines unserer DAG-Generierungsskripte ungewöhnlich lange Parsing-Zeiten. Dies wollen wir uns hier mal etwas näher ansehen1.
Allgemeiner Kontext
In Airflow 3 werden die meisten Metadatenabfragen über die API abgewickelt, einschließlich des Zugriffs auf Variables und Connections.
Aktueller Stand unseres Skripts
Wir verwenden ein Skript zur dynamischen Generierung von DAGs. Insgesamt haben wir etwa 700 DAGs, von denen ca. 650 auf diese Weise erzeugt werden.
Das Skript funktioniert grob wie folgt:
- Notwendige Metadaten laden
Abrufen der benötigten Daten aus der Datenbank. - ETL-Konfigurationsobjekte erstellen
Erstellen einer Liste von ETL-Konfigurationsobjekten, wobei jedes Objekt einen Job repräsentiert und sich aus den in 1 geladenen Laden zusammenbaut . - Über alle Konfigurationen iterieren
Dynamische Generierung der DAGs.- 3.1 Initialisierung des Setups
Validierung der Konfiguration und Ableitung von Attributen. - 3.2 Konstruktion von DAG und Tasks
- Erstellen der DAG-Instanz
- Initialisierung eines Resource Managers pro Job
- Aufbau der Task-Strukturen abhängig vom Job-Typ
- 3.1 Initialisierung des Setups
Wir haben auch bereits einige allgemeine Optimierungen vorgenommen:
- Caching von Datenbankabfragen, um wiederholte Zugriffe zu vermeiden (Schritt 1)
- Verwendung von AirflowParsingContext und Lazy Initialization, um unnötiges Parsen des Skriptes während der Task-Ausführung zu vermeiden (Schritt 3.1, siehe auch https://hungsblog.com/en/technology/troubleshooting/airflow-fill-dagbag-takes-too-long/)
Diese Verbesserungen reduzieren hauptsächlich den Overhead während der Task-Ausführung, nicht jedoch beim DAG-Parsing selbst.
Optimierung des DAG-Parsings
Die folgenden Optimierungen zielen auf die Phase der DAG-Konstruktion ab. Die gemessenen Parsing-Zeiten wurden für jede DAG-Erstellung in Schritt 3.2 erhoben. Es gibt daher praktisch einen leichten zusätzlichen Overhead aus Schritt 1, der zur Gesamtzeit hinzugerechnet werden muss.
Optimierungsschritte
Die folgenden Optimierungen wurden schrittweise eingeführt:
- Raw (nicht funktionsfähig)
Ohne vorherige Optimierung und Caching der Datenbankabfragen läuft das Skript nicht durch. Bei über 600 DAGs summieren sich selbst kurze Abfragezeiten und führen zu DAG-Parsing-Timeouts. - Noopt (baseline)
Nicht optimierte Version. DB Abfragen werden zwar gecacht, aber Variablen, Connections und abgeleitete Eigenschaften werden während des Parsings aufgelöst. - Novar
Lazy Loading von Variablen und Verlagerung von Berechnungsfunktionen in die Task-Ausführung statt in das DAG-Parsing.
Jeder Job-Typ hatte etwa 1–2Variable.get-Aufrufe, die dadurch eingespart werden konnten. - Nocalc
Entfernung von Property-Berechnungen (z. B. Datei-Lesen, DataFrame-Filterung). Diese basierten zwar auf gecachten Daten, verursachten aber dennoch zusätzlichen Overhead. - Nocon
Der Resource Manager wurde pro DAG-Konfiguration instanziiert und rief Connection-Daten über API-Aufrufe ab (wobei nicht alle Job-Typen einen Resource Manager besassen). Wir haben ihn so umgebaut, dass Daten gecacht und wiederverwendet werden können. - Novar2
Entfernung zusätzlicherVariable.get-Aufrufe in einem spezifischen Job-Typ (welcher 104 DAG Instanzen erzeugte). - Redcon (globale Optimierung)
Einführung einer Singleton Connection Factory.
Anstatt in jeder SchleifeBaseHook.get_connectionfür job-spezifische Eigenschaften aufzurufen, werden Airflow-Connection-Objekte nach dem ersten Abruf gecacht, um wiederholte API-Aufrufe zu reduzieren.
Ergebnisse
Jeder Optimierungsschritt wurde dreimal ausgeführt. Die Parsing-Zeit für jede DAG-Generierung wurde über diese drei Läufe gemittelt und anschließend erneut gemittelt, um die gesamtdurchschnittliche Parsing-Zeit (avg_parse_time) zu berechnen.
| optimization_step | avg_parse_time in s | |
| 0 | noopt | 46.726 |
| 1 | novar | 19.560 |
| 2 | nocalc | 19.031 |
| 3 | nocon | 7.452 |
| 4 | novar2 | 2.430 |
Nachfolgend ein Boxplot, der die Parsing-Zeit pro DAG zeigt (gemittelt über drei Läufe):
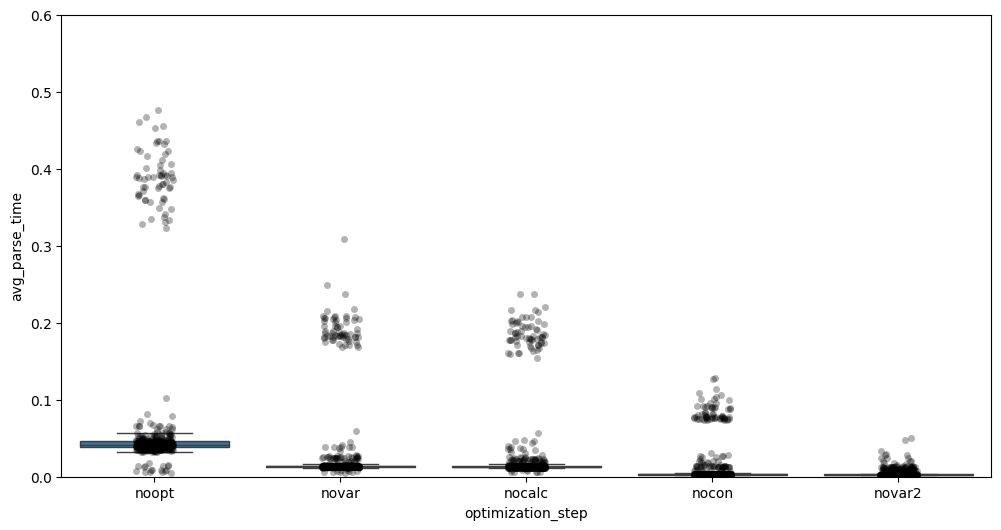
- NOOPT: Man kann in der baseline erkennen, dass es mehrere DAGs gibt, die deutlich längere Parsing-Zeiten besitzen. Vermutlich gehören sie zum selben Job-Typ.
- NOVAR: Reduzierung von Variable.get() bezogenen Aufrufen führt bereits zu einer spürbaren Verbesserung.
- NOCALC: Entfernen zusätzlicher Berechnungen und Funktionsaufrufe hat kaum Einfluss.
- NOCON: Reduktion von Connection-bezogenen API-Aufrufen führt zu einem weiteren deutlichen Rückgang der Parse Zeit.
- NOVAR2: Nach weiterer Reduktion von Variable.get() Aufrufen werden die Parsing-Zeiten deutlich homogener.
Die Redcon-Optimierung hatte keinen Einfluss auf die Parsing-Zeit pro DAG, reduzierte jedoch die Gesamtlaufzeit des Skripts um etwa 20 Sekunden (hauptsächlich in Schritt 2).
Diskussion
Der eigentliche Performance-Engpass beim DAG-Parsing sind API-Aufrufe. Das ist nicht überraschend (wird auch im Airflow Optimization Guide erwähnt), aber richtig deutlich wird der Effekt erst, wenn viele DAGs erzeugt werden. Jeder einzelne Aufruf verursacht nur geringen Overhead, summiert sich jedoch schnell, wenn viele DAGs erzeugt werden. Daher sollten API-Aufrufe während der DAG-Generierung möglichst vermieden und stattdessen in die Task-Ausführung verlagert werden, beispielsweise in Operatore
Dieser Effekt wird weiter verstärkt, wenn AirflowParsingContext nicht verwendet wird, um das Parsing während der Task-Ausführung auf das notwendige Minimum zu beschränken. In diesem Fall führt jede Task-Ausführung zur Ausführung des gesamten Skripts inklusive aller API-Aufrufe, was effektiv einem DOS-Angriff auf den eigenen API-Server entspricht.
Auch wenn die REDCON-Optimierung keinen Einfluss auf die Parsing-Zeit pro DAG hatte, reduzierte sie die Gesamt-Parsing-Zeit deutlich. Bei über 600 DAGs, aber nur etwa 40 unterschiedlichen connection_ids, summieren sich wiederholte API-Aufrufe schnell. Durch das Caching dieser Verbindungen nach dem ersten Abruf lassen sich hunderte redundante API-Aufrufe vermeiden, was zu einer erheblichen Zeitersparnis führt. Das unterstreicht, wie wichtig es ist, gemeinsam genutzte Metadaten wie z.B. Connection Informationen nach Möglichkeit zu cachen.
Zusätzlich führen stärker dynamische Jobs zu häufigeren Änderungen in den DAG-Definitionen. In Kombination mit dem DAG Versionierung von Airflow 3 kann dies zu einer sehr großen Anzahl von DAG-Versionen führen (siehe entsprechendes GitHub-Issue).
Wenn du auch schon einmal mit Performance- oder Optimierungsproblemen in Airflow zu kämpfen hattest oder dir dieser Beitrag weitergeholfen hat, freue ich mich über einen Kommentar!
- Dieser Blog Post wurde mit ChatGPT 5.3 von Englisch ins Deutsche übersetzt ↩︎