Im Deutschen gibt es Sonderzeichen, die als Umlaute bekannt sind, unter anderem z.B. ä, ü, ö. Wenn das System nicht korrekt eingestellt ist, kann die Kodierung dieser Zeichen zu einem Informationsverlust führen. Sehen wir uns ein praktisches Beispiel an, bei dem eine solche Fehlkonfiguration zu Problemen in einer Spark-Pipeline geführt hat.
Das System
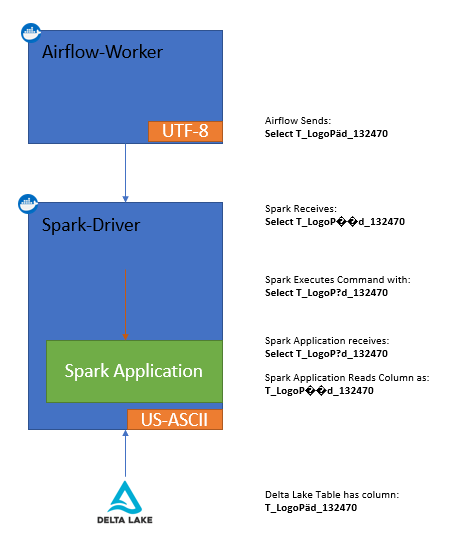
Ich bin derzeit mit einem System beschäftigt, das wie in der Abbildung unten dargestellt ist. Airflow orchestriert einen ETL-Job, den Spark ausführt. Bei diesem Prozess übergebe ich eine SQL-Anweisung als Argument an Spark. Der Spark Driver empfängt dieses Argument und führt den Code innerhalb seiner Anwendung aus. Aufgrund des Informationsverlustes, wegen der unterschiedlichen Kodierungsunterstützung, bricht die Spark Pipeline allerdings ab.

Troubleshooting & Fixing
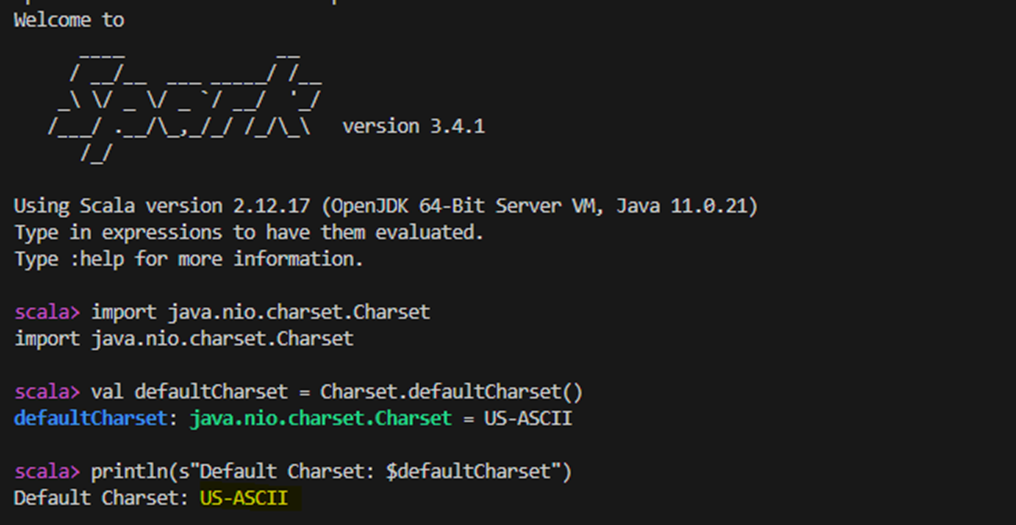
Wenn ich auf meinen Spark-Container zugreife, die spark-shell ausführe und mir den Zeichensatz ausgeben lasse, so meldet er tatsächlich: US-ASCII. Dies deutet darauf hin, dass die standardmäßige Zeichenkodierung zu einem gewissen Informationsverlust beitragen könnte, insbesondere in diesem Fall, in dem die SQL-Anweisungen Zeichen enthalten, die von US-ASCII nicht unterstützt werden.
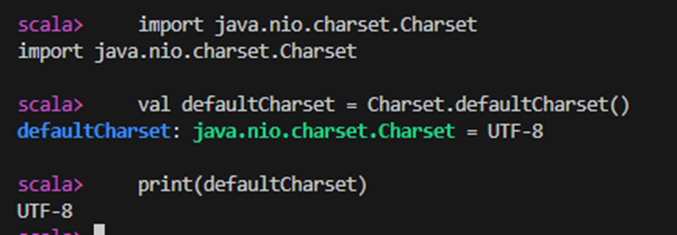
import java.nio.charset.Charset
val defaultCharset = Charset.defaultCharset()
print(defaultCharset)
Also habe ich die Ratschläge von stackoverflow (und chatgpt) befolgt, welche vorschlagen, die lokale Zeichenkodierung zu konfigurieren. Ich habe also Folgendes ausgeführt:
apt-get install -y locales && rm -rf /var/lib/apt/lists/* && locale-gen en_US.UTF-8
export LANGUAGE="en_US:en„
export LANG="en_US.UTF-8“
export LC_ALL="en_US.UTF-8"
Beim letzten Export erhielt ich jedoch eine Warnung:
bash: warning: setlocale: LC_ALL: cannot change locale (en_US.UTF-8)

Bei einer erneuten Überprüfung der Zeichenkodierung in der spark-shell zeigte sich, dass die Konfigurationsänderungen keine Auswirkungen hatten. Außerdem löste der Prozess einige Warnungen aus.

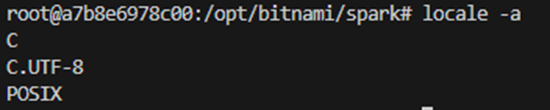
Nach dem googln der Fehlermeldung zeigt sich, dass scheinbar die Locals noch nicht kompiliert wurden (stackexchange). Auch nachzusehen in diesem Kommentar. Und in der Tat gab die Ausführung von locale -a kein en_US.UTF-8 an.
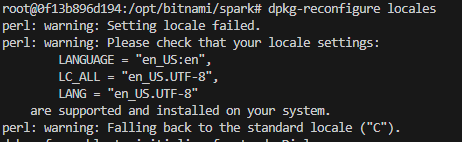
Um sie zu kompilieren, könnten wir dpkg-reconfigure locales ausführen, aber dann müssten wir durch eine interaktive Shell gehen. (Wir werden hier freundlicherweise auch wieder darauf hingewiesen, dass die von uns konfigurierte Kodierung en_US.UTF-8 möglicherweise noch nicht auf dem System installiert ist.)
Da wir die Zeichenkodierung am Ende in einem Dockerfile implementieren wollen, brauchen wir etwas besser geeignetes, ohne die Notwendigkeit eines manuellen Eingriffes. Witzigerweise kehre ich auf der Suche nach einem Ersatz für die Kompilierung über die Interaktive Shell zu meiner allerersten stackoverflow-Antwort zurück: sed -i '/en_US.UTF-8/s/^# //g' /etc/locale.gen && locale-gen
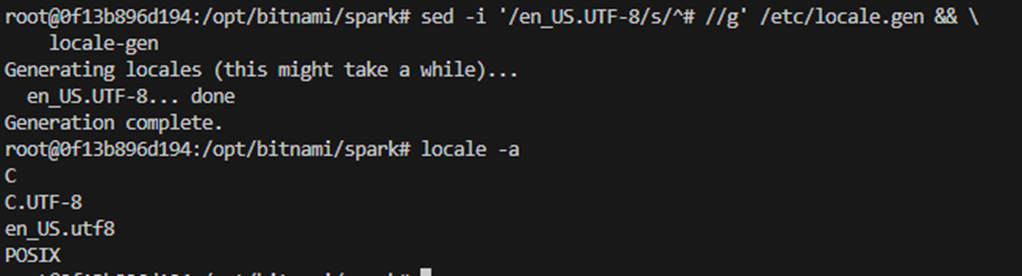
Am Ende müssen wir nur noch die Umgebungsvariablen festlegen, und Schwupp-di-Wupp, wird der Zeichensatz in der JVM geändert, und das sogar ohne Neustart.
Finales Dockerfile Snippet
Wir implementieren unsere Erkenntnisse in das Dockerfile. Das resultierende Snippet sieht wie folgt aus:
RUN apt-get install -y locales && rm -rf /var/lib/apt/lists/* \
&& sed -i '/en_US.UTF-8/s/^# //g' /etc/locale.gen && \
locale-gen
ENV LANG en_US.UTF-8
ENV LANGUAGE en_US:en
ENV LC_ALL en_US.UTF-8
Und das war’s, wir haben en_US.UTF-8 erfolgreich auf unserem Spark-Image installiert und konfiguriert.