Machine Learning Engineering

Signalverarbeitung – Filter
Da ich noch nie wirklich mit Signalen gearbeitet habe, brauchte ich zunächst ein grundlegendes Verständnis von Filtern. Im Folgenden sind meine Notizen über Tiefpass- und Hochpassfilter aus dem Youtube-Video von ritvikmath. Terminologie Low-Pass und High-Pass Filter Low-Pass Filter High-Pass Filter…

Wie man zwei Zeitstempel in gleiche Teile teilt
Wie kann man gleichmäßige Zeitabstände zwischen zwei Zeitstempeln erzeugen?
Pytorch – Skalartyp Float erwartet, aber Double gefunden
TLDR: Der Standard-Datentyp eines Numpy-Arrays ist double/float64. Wenn ein Tensor aus diesem Array mit torch.as_tensor() erstellt wird, nimmt er diesen Datentyp an. Der Standarddatentyp eines neuronalen Netzwerkmodells ist allerdings float32. Die Verwendung des float64 Tensors als Eingabe für das NN-Modell…
Fehler beim Training eines Languagemodels – RuntimeError the expanded size of the tensor (100) must match the existing size (64) at non singleton dimension 1.
Kontext Ich habe ein neues Sprachmodell von Grund auf mit dem Huggingface-Frameworkes und einem vorkonfiguriertem Roberta-Modells auf einem eigenen Datensatz trainiert. Nun wollt ich einen neuen Datensatz mit Hilfe des trainierten Modells vektorisieren. Beobachtung Es trat ein Fehler auf: Auflösung…
SentenceTransformer – float object is not subscriptable
TLDR: np.nan Objekte sind fom Typ float Beobachtung Um numerische Repräsentationen für Dokumente (sogenannte Embeddings) zu erstellen habe ich mich dem SentenceTransformer (v2.2.0) bedient, allerdings wurde in vereinzelten Fällen der Fehler “TypeError: ‘float’ object is not subscriptable” geworfen. Der traceback…
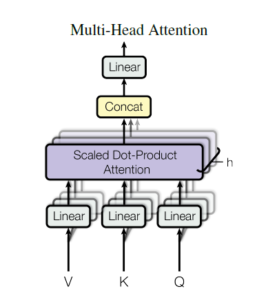
Visuelle Erklärung der Multi-Head Attention
Warum ändert sich bei einer Änderung der Anzahl der Heads eines Transformermodell nicht dessen Anzahl an Parametern? – Das war die Frage, die ich mir gestellt habe. Nachdem ich die entsprechende Matrizenmultiplikation nachvollzogen und zu einem entsprechendem Ergebnis gekommen bin,…
Evaluierung des Trainers der Transformer Bibliothek
Innerhalb des Transformer Frameworkes kann ein Trainer Objekt lästigen Code für die Konfiguration der Traningspipeline einsparen. Mit den TrainingArguments können zusätzliche Parameter eingestellt werden. Eine der wichtigen Argumente ist die evaluation_strategy, welche als Standartwert “no” besitzt. Dies besagt, dass keine…
Unterschied zwischem dem Tokenizer und PreTrainedTokenizer
Da ich recht zufällig in des Transformers framework reingezogen wurde, hatte ich anfangs einige Probleme gehabt, die verschiedenen Komponenten zu verstehen. In diesem Beitrag würde ich gerne mein Verständnis zum Tokenizer teilen und wie man special_tokens einbauen kann, um sie…

Objekterkennung – Ein Überblick zur Mean Average Precision (mAP)
Um die Performance verschiedener Modelle in der Objekterkennung vergleichbar zu machen ist eine einfache lesbare Metrik vorteilhaft. In diesem Beitrag wird die Mean Average Precision (mAP) vorgestellt.