Da ich recht zufällig in des Transformers framework reingezogen wurde, hatte ich anfangs einige Probleme gehabt, die verschiedenen Komponenten zu verstehen. In diesem Beitrag würde ich gerne mein Verständnis zum Tokenizer teilen und wie man special_tokens einbauen kann, um sie später in einem languagemodel Training zu verwenden. Achtung. Dies sind meine eigenen Notizen und Verständnis zu dem Thema 🙂
TLDR: Die Tokenizer und PreTrainedTokenizer Klassen übernehmen unterschiedliche Rollen. Der Tokenizer ist eine Pipeline und definiert den Prozess der Tokenisierung, während der PreTrainedTokenizer mehr eine Art Wrapper um den Tokenizer ist, um zusätzliche Funktionalitäten bereitzustellen, welche durch andere Komponenten des 🤗 Transformers Frameworks genutzt werden.
Was sind Tokenizer?
Anders als Menschen können Maschinen nur mit numerischen Werten arbeiten. Damit sie also Wörter verstehen und verarbeiten können, müssen diese zunächst in ihre nummerischen Gegenstücke übersetzt (tokenisiert) werden. Es gibt viele verschiedene Arten der Tokenisierung (z. B. WordPiece, BPE), aber das Grundprinzip bleibt immer das gleiche und zwar einen Text mit Wörtern und Zeichen in eine Reihe numerischer Werte zu transformieren.
Die Tokenizer Klasse (🤗 Tokenizer)
“A Tokenizer works as a pipeline, it processes some raw text as input and outputs an Encoding.” (🤗 Tokenizer). Die Pipeline Schritte sind wie folgt:
- Normalizer: normalisiert den Eingabetext z.B. Kleinbuchstaben, Ersetzen von Zeichen
- Pretokenizer: trennt den Text in Wörter auf z.B. anhand des Leerzeichens. Das Ergebnis ist eine Liste von Tupeln mit Wörtern und ihrer Position im Text
- Model: Der eigentliche Tokenisierungsalgorithms (z.B. WordPiece). In Abhängigkeit des Algorithmuses und der Trainingsdaten, kann es vorkommen, dass Wörter in weitere kleinere Bestandteile zerlegt werden
- PostProcessor: Fügt weitere relevante Bausteine der kodierten Sequenz hinzu z.B. ein [CLS] Token an jedem Anfang, welches für das Training des Sprachmodels notwendig ist.
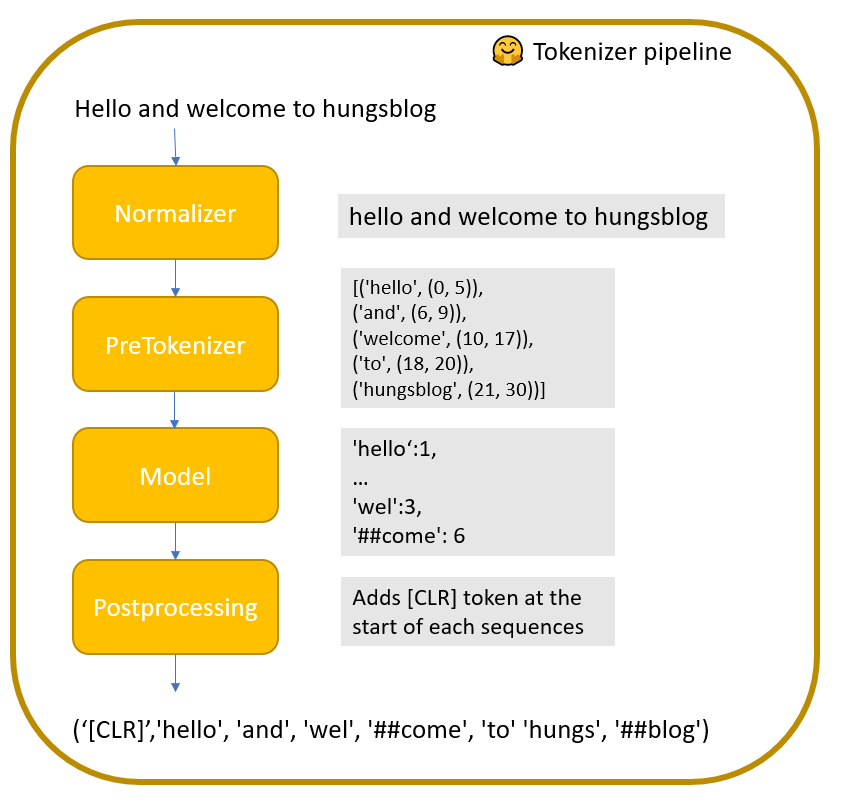
Natürlich ist es möglich, eine eigene Tokenizer Pipeline zu konfigurieren und auf Daten zu trainieren. Abhängig von den Trainingsdaten, erstellt das Model unterschiedliche Token. Es gibt bereits einige Tutorials, die zeigen, wie man einen Tokenizer von Grund auf neu erstellen kann (siehe google colab notebook). Dies erlaubt es dann auch, die Vokabelgröße und die special_tokens festzulegen.
Die vordefinierte Pipeline sowie antrainierten Token können dann als json gespeichert werden.
Die PreTrainedTokenizer Klasse (🤗 Transformers)
Die PreTrainedTokenizer Klasse dient mehr als Wrapper um ein bereits existierendes Tokenizer Modell und stellt zusätzliche Funktionalitäten bereit, die von anderen Komponenten des Transformer Frameworks genutzt werden. Beispielsweise greift der DataCollatorForLanguageModeling auf die get_special_token() Funktion des Tokenizers zu, um eine Maske zu erhalten, die notiert, an welcher Position sich special_tokens befinden.
Zusätzlich kann der PreTrainedTokenizer auch individuell konfiguriert werden. Wenn beispielsweise ein BERT Model trainiert werden soll, müssen vorher noch special tokens definiert werden, die das Model interpretieren und als Marker nutzen kann ([MASK], [CLS], etc).
Beim Speichern des PreTrainedTokenizers wird ein Ordner mit drei Dateien erstellt:
- Eine tokenizer.json, welche den gleichen Inhalt besitzt, wie die vom Tokenizer generierte Datei
- Eine special_tokens_map.json, welche das Mapping von special_token zu den bereits erwähnten Markern und ihrer Funktionalität besitzt. Diese wird beispielsweise durch die Funktion
get_special_tokens_mask() - eine weitere Konfigurationsdatei
Wie special_tokens dem PreTrainedTokenizer hinzugefügt werden
Um zusätzliche special_tokens (aus welchen Gründen auch immer) hinzuzufügen, kann eine Liste von benutzerdefinierten special_tokens der additional_special_tokens property des PreTrinedTokenizer Objektes zugeordnet werden.
tokenizer.additional_special_tokens=['list','of','custom','special','attributes']
Wenn nun der PreTrainedTokenizer gespeichert wird, kann dieses neue Mapping auch in der entsprechenden special_tokens_map.json eingesehen werden. Das ist besonders wichtig, da nun ein zu trainierendes languagemodel Informationen zu den genutzten und vorhandenen special_tokens besitzt und ihnen in bestimmten Fällen Funktionalität zuweisen oder sie beispielsweise beim masked language modelling task ignorieren kann.
Hinterlasst gerne einen Kommentar, wenn dieser Beitrag hilfereich gewesen sein sollte oder ihr Feedback geben möchtet 🙂