In our open-source data framework, which includes Apache Spark for data processing, Delta Lake for data management, and MinIO as S3 object storage, we aimed to integrate a Hive metastore. However, integrating the metastore turned out to be more complex than anticipated—largely because we lacked a clear understanding of what it was and how to use it without the full Hive ecosystem. Let’s break down our learnings step by step.
Motivation for Using Hive Metastore with Delta Lake
There are many guides that describe the Hive metastore and its role in the Hive ecosystem, such as this one. But what exactly is its benefit in our specific use case?
“Metastore (aka metastore_db) is a relational database that is used by Hive, Presto, Spark, etc. to manage the metadata of persistent relational entities”
For example, when we save a table in MinIO, we access it through its full path, such as:
SELCT * FROM delta.`s3a://bucket1/hungs/blog/table
This method can be cumbersome and lacks the convenience of schemas and short names, similar to those in RDBMS systems. The metastore solves this problem by mapping the path to a schema and table name. In practice, this enables SQL-like queries to be run against Delta Lake tables without worrying about the underlying storage paths. While the Hive metastore offers additional features, this basic functionality alone provides a strong enough motivation to integrate it into our setup.
General understanding
Looking through the internet, I came across two blog posts that enhanced my understanding of the metastore catalogs (@sarfarazhussain211, medium) and how to set them up in a Spark-Delta-Lake environment (@howdyservices9, medium). Although these posts provide hands-on guidance, I felt still confused as they still lack a high-level overview for those who have never worked with the Hive metastore. To address this, I’ve broken down the concepts and options in this section.
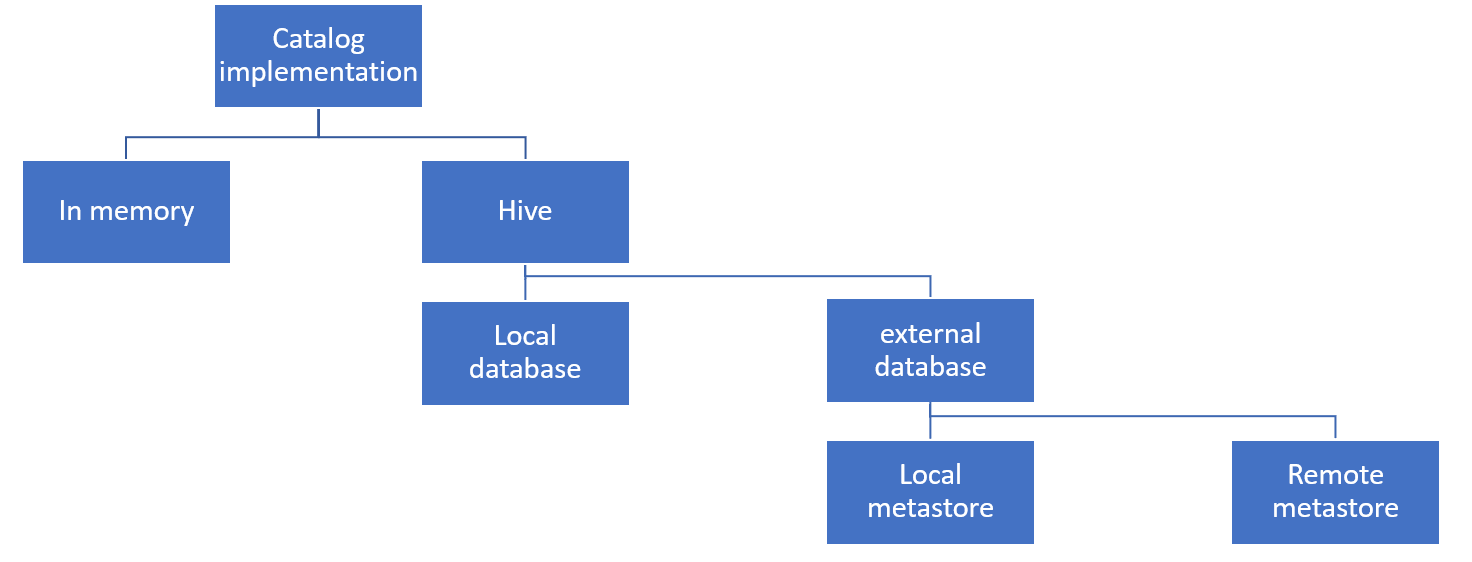
Spark can handle metadata using two options: in-memory or Hive. The in-memory catalog manages views and tables created during Spark execution, but it doesn’t persist across sessions. The hive catalog on the other hand persists meta data in “the metastore”.
This metastore can be configured to use either the local Derby database, which is a lightweight, built-in solution where the metadata is stored locally. While the Derby database is the default, it is not suitable for production due to its single-user mode and lack of scalability (@sarfarazhussain211, medium). For production environments, you’ll want to configure an external database, such as PostgreSQL or MySQL.
How to Configure the Hive Metastore for Apache Spark
Now that we understand the basics, we can determine which setup to use and what configuration options are required.
1. No metastore – In-Memory
This is where the Databricks guide comes into play, outlining two modes of operation: local and remote. However, the Databricks guide’s use of “remote” and “local” can be a bit confusing. These terms refer to the location of the metastore service, not the database. In the local setup, the metastore service runs within Spark’s environment, while in the remote setup, the service runs independently and communicates with Spark over the network. In both cases, an external database (e.g., PostgreSQL) is used for metadata storage.
In this case, no configuration is needed, as Spark automatically uses the in-memory catalog (stackoverflow).
spark.sql.catalogImplementation=in-memory2. Yes Metastore – Local Database – Derby
When configuring the Hive catalog, a default local Derby database is used unless otherwise specified.
spark.sql.catalogImplementation=hive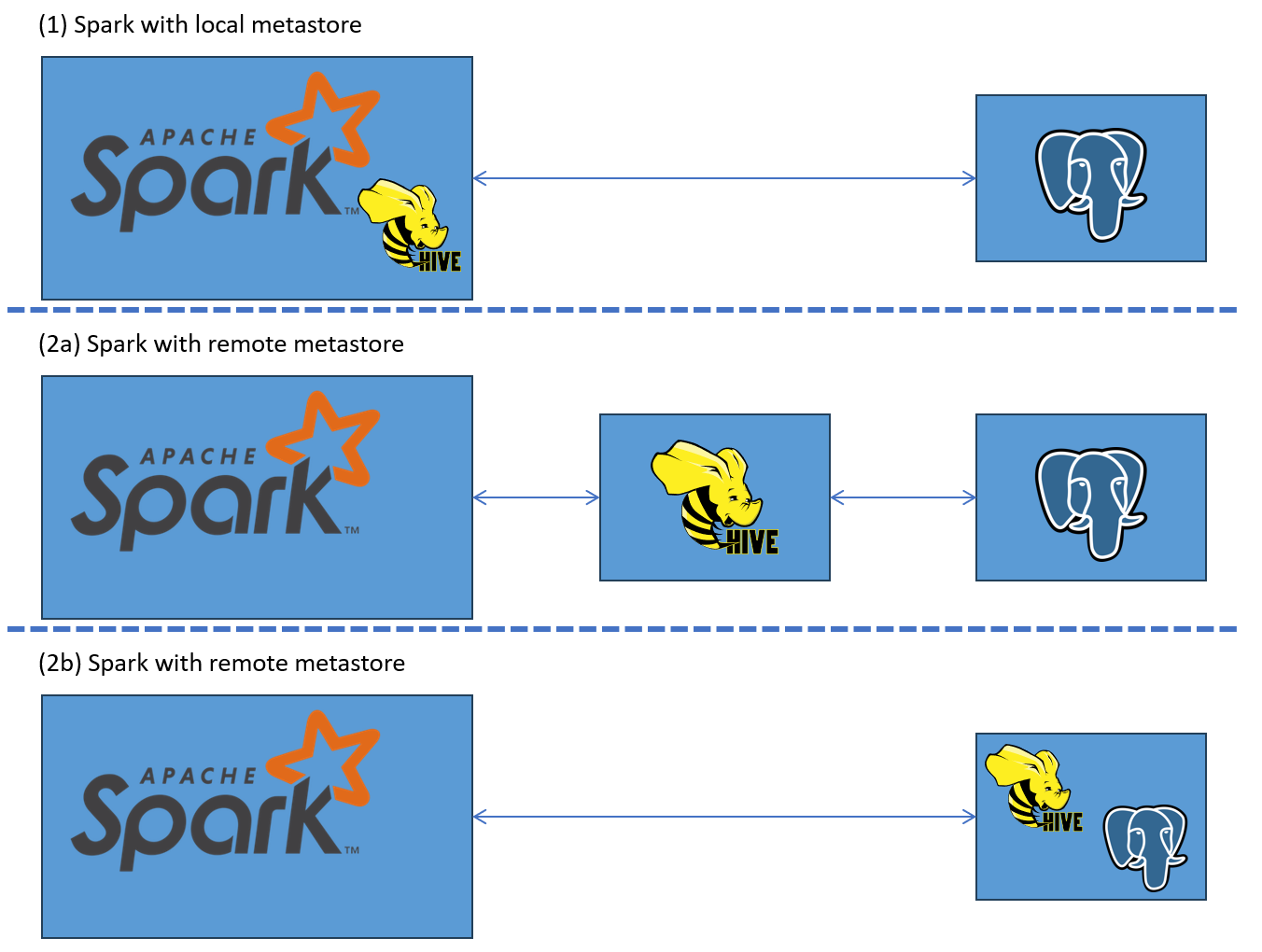
3. Yes Metastore – External Database – Local Metastore Service
If you choose to run the metastore service locally (within Spark’s environment), you must provide the configuration for the external database (e.g., PostgreSQL) where the metadata will be stored (databricks). In the figure below, this setup is represented by (1).
spark.sql.catalogImplementation=hive
javax.jdo.option.ConnectionURL=jdbc:mysql://<metastore-host>:<metastore-port>/<metastore-db>
javax.jdo.option.ConnectionUserName=<mysql-username>
javax.jdo.option.ConnectionPassword=<mysql-password>
javax.jdo.option.ConnectionDriverName=org.mariadb.jdbc.DriverThis can be configured through the spark-defaults.conf, the Spark session, or the hive-site.xml file.
4. Yes Metastore – External Database – Remote Metastore Service
If Spark is configured to connect to a remote Hive Metastore service, you only need to provide Spark with the connection details to the metastore service. The metastore service itself should already be configured to connect to the external database (i.e. contain the connection information as in 3.). The remote metastore service will handle metadata requests and manage the connection to the PostgreSQL database.
spark.sql.catalogImplementation=hive
spark.hadoop.hive.metastore.uris=thrift://<metastore-host>:<metastore-port>This can be configured through spark-defaults.conf, the Spark session, or the hive-site.xml file.
Typically, the metastore service operates as a separate entity that connects to an externally located database (see 2a). An example of this is the original Hive Docker Compose deployment. However, it is also possible for the metastore service and the database to reside within the same environment (see 2b), as demonstrated in this repository. In an unusual case, this repository runs option 2b but uses the local Derby database instead of an external one.
What is the “Metastore Service” anyway?
We talked a lot about the metastore service, but what is it anyway? It is the logic and software to handle and manage the metadata. It originally began as part of the Apache Hive project, but starting with Hive version 3.0, it was separated into its own project (see HIVE-17159). Throughout its versions, the metastore has also evolved. Schema changes are tracked here: GitHub – Apache Hive Schema Changes.
In both the local and remote metaservice deployment approach (3 and 4), the system which want to communicate with the metastore database reqiuires as the minium the spark-hive.jar. It has transitive dependencies to the hive-metastore and hive-exec libraries, which are fundamental for the metastore service. As of Spark-Hive version 3.5.2, it includes transitive dependencies on Hive-Metastore and Hive-Exec version 2.3.9 (see maven repository). The version of the remote Hive Metastore service (e.g. currently 4.0.0) does not need to match the version of the Hive-Metastore included in the Spark-Hive library, as the metastore service appears to be backwards compatible.
Why Decouple the Metastore Service?
- Different Spark Version Usage:
- By decoupling the metastore service, you can run different versions of Spark while still using the same central metastore. This is useful when managing multiple Spark clusters or environments with varying versions, as it avoids compatibility issues that may arise from tightly coupling the metastore to Spark.
- Centralized Metadata Management:
- A remote metastore service allows you to create a single point for managing all metadata requests. This centralization is especially beneficial when multiple services (e.g., Hive, Presto, Spark) need to access the same metadata. It ensures consistency across platforms and simplifies management and updates to the metastore.
Keep in mind that if you have a local metastore service within your Spark application, your local development environment must be able to access the metastore database (PostgreSQL) and include all necessary dependencies. In contrast, with a remote metastore, you only need access to the metastore service itself, which will handle the connection to the database in the background.
And that’s about it! If this overview helped clarify your understanding of the Hive metastore and its integration with Spark, feel free to leave a comment or share your thoughts!