In unserem Open-Source Framework, welches Apache Spark für die Datenverarbeitung, Delta Lake für das Datenmanagement und MinIO als S3-Objektspeicher nutzt, wollten wir einen Hive Metastore integrieren. Die Integration stellte sich jedoch als komplexer heraus als erwartet, einfach weil uns ein klares Verständnis davon fehlte, was er eigentlich ist und wie man ihn ohne das vollständige Hive-Ökosystem nutzt. In diesem Beitrag würde ich gerne die Erkenntnisse Schritt für Schritt niederschreiben 1.
Dieser Post wurde mit ChatGpt 5.3 vom Englischen ins Deutsche übersetzt.
Motivation für die Nutzung des Hive Metastore mit Delta Lake
Es gibt viele Anleitungen, die den Hive Metastore und seine Rolle im Hive-Ökosystem beschreiben, wie zum Beispiel diese hier. Aber welchen konkreten Nutzen hat er in unserem Anwendungsfall?
“Metastore (aka metastore_db) is a relational database that is used by Hive, Presto, Spark, etc. to manage the metadata of persistent relational entities”
Wenn wir beispielsweise eine Tabelle in MinIO speichern, greifen wir über ihren vollständigen Pfad darauf zu, etwa so:
SELCT * FROM delta.`s3a://bucket1/hungs/blog/table
Diese Methode kann umständlich sein und bietet nicht die leichte Handhabung mit Schemas und kurzen Tabellennamen, wie man sie aus RDBMS-Systemen kennt. Der Metastore löst dieses Problem, indem er den Pfad einem Schema- und Tabellennamen zuordnet. In der Praxis ermöglicht dies SQL-ähnliche Abfragen auf Delta-Lake-Tabellen, ohne sich um die zugrunde liegenden Speicherpfade kümmern zu müssen. Auch wenn der Hive Metastore weitere Funktionen bietet, ist allein diese grundlegende Funktionalität bereits ein starkes Argument für seine Nutzung.
Allgemeines Verständnis
Bei meiner Recherche bin ich auf zwei Blogbeiträge gestoßen, die geholfen haben, ein besseres Verständnis von Metastore-Katalogen (@sarfarazhussain211, Medium) und deren Einrichtung in einer Spark-Delta-Lake-Umgebung (@howdyservices9, Medium) zu erhalten. Obwohl diese Beiträge praxisnahe Anleitungen bieten, fehlte mir dennoch ein Gesamtüberblick, insbesondere für Anwender, die noch nie mit dem Hive Metastore gearbeitet haben. Deshalb habe ich die Konzepte und Optionen in diesem Abschnitt aufgeschlüsselt.
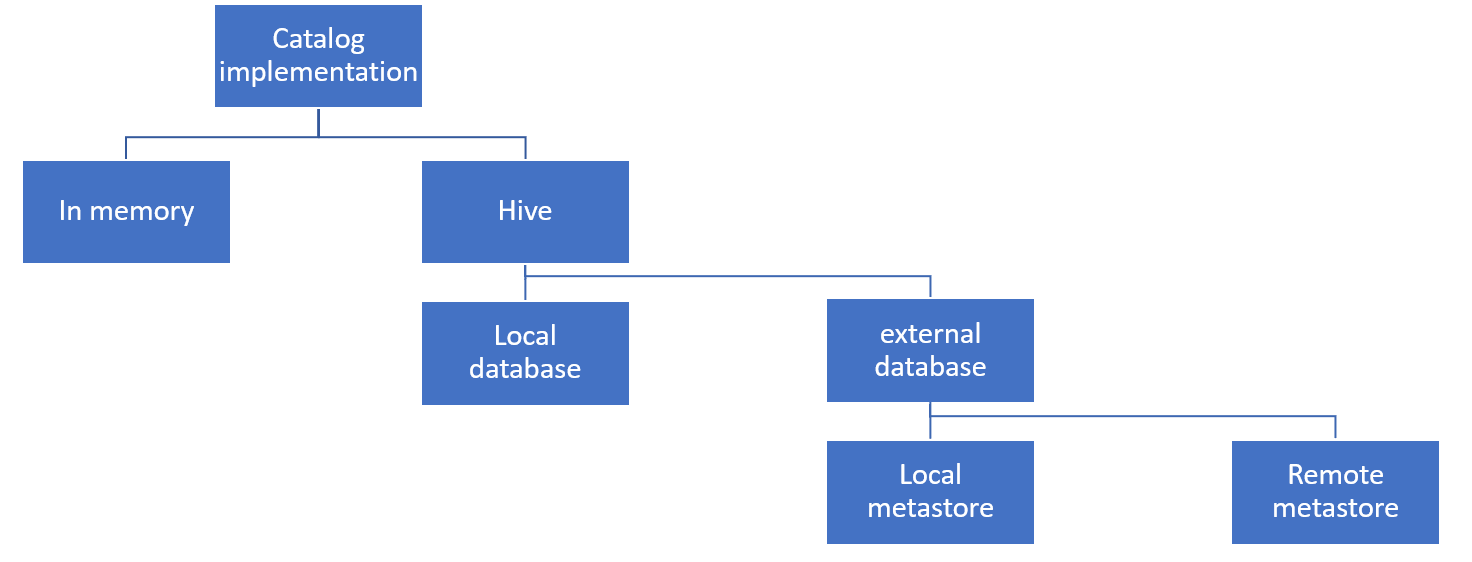
Spark kann Metadaten auf zwei Arten verwalten: im Speicher (in-memory) oder über Hive. Der In-Memory-Katalog verwaltet Views und Tabellen, die während der Spark-Ausführung erstellt werden, persistiert diese jedoch nicht über Sitzungen hinweg. Der Hive-Katalog hingegen speichert Metadaten dauerhaft im „Metastore“.
Dieser Metastore kann wiederum so konfiguriert werden, dass entweder die lokale Derby-Datenbank verwendet wird – eine leichtgewichtige, integrierte Lösung, bei der die Metadaten lokal gespeichert werden. Obwohl Derby die Standardoption ist, eignet sie sich aufgrund ihres Single-User-Modus und mangelnder Skalierbarkeit nicht für den produktiven Einsatz (@sarfarazhussain211, Medium). Für produktive Umgebungen sollte stattdessen eine externe Datenbank wie PostgreSQL oder MySQL konfiguriert werden.
Konfiguration des Hive Metastore für Apache Spark
Nachdem wir die Grundlagen verstanden haben, können wir entscheiden, welches Setup wir verwenden und welche Konfigurationsoptionen erforderlich sind.
1. Kein Metastore = In-Memory
Hier kommt die Databricks-Dokumentation ins Spiel, die zwei Betriebsmodi beschreibt: lokal und remote. Die Begriffe „lokal“ und „remote“ können dabei etwas verwirrend sein, da sie sich auf den Ort des Metastore-Services beziehen und nicht auf die Datenbank. Beim lokalen Setup läuft der Metastore-Service innerhalb der Spark-Umgebung, beim Remote-Setup läuft er unabhängig und kommuniziert über das Netzwerk mit Spark. In beiden Fällen wird eine externe Datenbank (z. B. PostgreSQL) für die Speicherung der Metadaten verwendet.
In diesem Fall ohne Metastore ist keine Konfiguration erforderlich, da Spark automatisch den In-Memory-Katalog verwendet (Stack Overflow):
spark.sql.catalogImplementation=in-memory2. Metastore – Lokale Datenbank – Derby
Bei der Konfiguration des Hive-Katalogs wird standardmäßig eine lokale Derby-Datenbank verwendet, sofern nichts anderes angegeben ist:
spark.sql.catalogImplementation=hive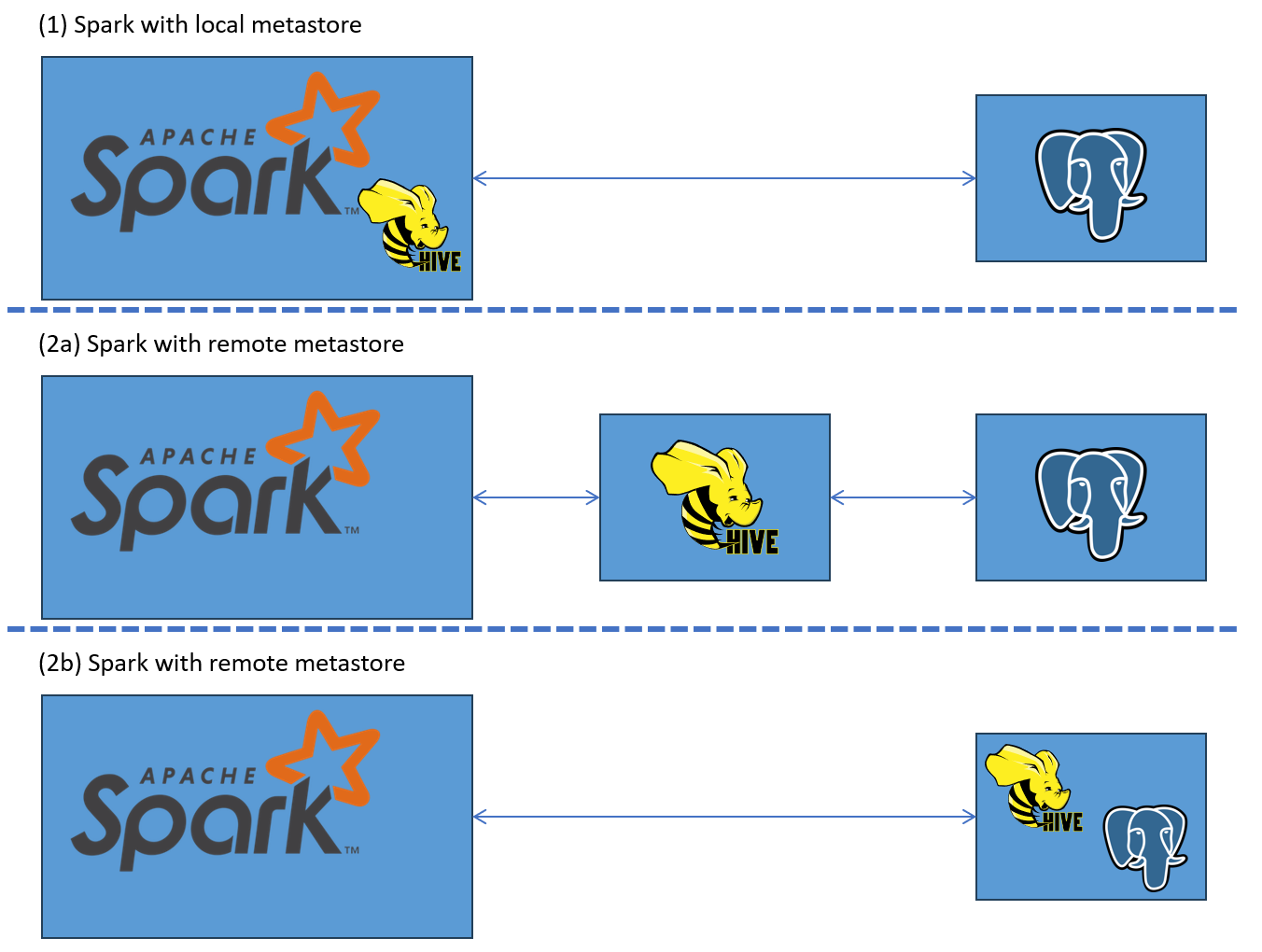
3. Metastore – Externe Datenbank – Lokaler Metastore-Service
Wenn der Metastore-Service lokal (innerhalb der Spark-Umgebung) betreiben soll, muss die Konfiguration für die externe Datenbank (z. B. PostgreSQL) angegeben werden, in der die Metadaten gespeichert werden (Databricks). In der Abbildung entspricht dies Setup (1).
spark.sql.catalogImplementation=hive
javax.jdo.option.ConnectionURL=jdbc:mysql://<metastore-host>:<metastore-port>/<metastore-db>
javax.jdo.option.ConnectionUserName=<mysql-username>
javax.jdo.option.ConnectionPassword=<mysql-password>
javax.jdo.option.ConnectionDriverName=org.mariadb.jdbc.DriverDies kann über die Datei spark-defaults.conf, die Spark-Session oder die Datei hive-site.xml konfiguriert werden.
4. Metastore – Externe Datenbank – Remote Metastore-Service
Wenn Spark so konfiguriert ist, dass es sich mit einem Remote Hive Metastore-Service verbindet, müssen lediglich die Verbindungsdaten zum Metastore-Service angegeben werden. Der Metastore-Service selbst sollte bereits so konfiguriert sein, dass er sich mit der externen Datenbank verbindet (also die Informationen wie in Punkt 3 enthält). Der Remote-Service übernimmt die Verarbeitung der Metadaten-Anfragen und verwaltet die Verbindung zur PostgreSQL-Datenbank.
spark.sql.catalogImplementation=hive
spark.hadoop.hive.metastore.uris=thrift://<metastore-host>:<metastore-port>Dies kann über die Datei spark-defaults.conf, die Spark-Session oder die Datei hive-site.xml konfiguriert werden.
Typischerweise läuft der Metastore-Service als separate Komponente, die mit einer externen Datenbank verbunden ist (siehe 2a). Ein Beispiel dafür ist das ursprüngliche Hive-Docker-Compose-Setup. Es ist jedoch auch möglich, dass sich Metastore-Service und Datenbank in derselben Umgebung befinden (siehe 2b), wie in diesem Repository gezeigt. In einem ungewöhnlichen Szenario verwendet dieses Repository zwar Setup 2b, nutzt jedoch die lokale Derby-Datenbank anstelle einer externen.
Was ist nun eigentlich dieser „Metastore Service“?
Wir haben viel über den Metastore-Service gesprochen, aber was ist das eigentlich? Es handelt sich um die Logik und Software zur Verarbeitung und Verwaltung von Metadaten. Ursprünglich war er Teil des Apache-Hive-Projekts, wurde aber ab Version 3.0 in ein eigenes Projekt ausgelagert (siehe HIVE-17159). Über die Versionen hinweg hat sich der Metastore weiterentwickelt. Änderungen am Schema werden hier dokumentiert: GitHub – Apache Hive Schema Changes.
Sowohl bei lokalem als auch bei remote Metastore-Service (Option 3 und 4) benötigt das System, das mit der Metastore-Datenbank kommunizieren möchte, mindestens die spark-hive.jar. Diese bringt transitive Abhängigkeiten zu den Bibliotheken hive-metastore und hive-exec mit, die grundlegend für den Metastore-Service sind. Ab Spark-Hive Version 3.5.2 werden die Versionen 2.3.9 benötigt (siehe Maven Repository). Die Version des Remote Hive Metastore-Service (z. B. aktuell 4.0.0) muss dabei nicht mit der Version in der Spark-Hive-Bibliothek übereinstimmen, da der Metastore-Service scheinbar abwärtskompatibel ist.
Warum den Metastore-Service entkoppeln?
- Nutzung unterschiedlicher Spark-Versionen
- Durch die Entkopplung des Metastore-Services können verschiedene Spark-Versionen verwenden werden und trotzdem denselben zentralen Metastore nutzen. Das ist besonders hilfreich beim Betrieb mehrerer Spark-Cluster oder Umgebungen mit unterschiedlichen Versionen, da Kompatibilitätsprobleme vermieden werden.
- Zentrale Verwaltung von Metadaten
- Ein Remote-Metastore-Service ermöglicht einen zentralen Zugriffspunkt für alle Metadaten-Anfragen. Diese Zentralisierung ist besonders vorteilhaft, wenn mehrere Dienste (z. B. Hive, Presto, Spark) auf dieselben Metadaten zugreifen müssen. Sie sorgt für Konsistenz über Plattformen hinweg und vereinfacht Verwaltung und Updates.
Wenn ein lokaler Metastore-Service innerhalb der Spark-Anwendung genutzt wird, muss potentiell die lokale Entwicklungsumgebung Zugriff auf die Metastore-Datenbank (z. B. PostgreSQL) haben und alle notwendigen Abhängigkeiten enthalten. Auf der anderen Seite, bei einem Remote-Metastore wird hingegen nur die Verbindung zum Metastore-Service selbst benötigt, der dann die Verbindung und Abhängigkeiten zur Datenbank im Hintergrund übernimmt.
Und das war’s im Wesentlichen! Wenn dir dieser Überblick geholfen hat, dein Verständnis des Hive Metastore und seiner Integration mit Spark zu verbessern, hinterlasse gerne einen Kommentar oder teile deine Gedanken!