I just got tossed into the cold water of the 🤗 Transformer framework and had some initial troubles with understanding the components. I’d like to write down my understanding of the Tokenizer and on how to add special_tokens to them, for use in later LM task. Disclaimer: These are my personal notes and understanding of the topic at hand.
TLDR: The Tokenizer and PreTrainedTokenizer classes perform different roles. The Tokenizer is a pipeline and defines the actual tokenization, while the PreTrainedTokenizer is more of a wrapper to provide additional functionality to be utilized by other components of the 🤗 Transformer library.
What are Tokenizers?
Unlike humans, machines can only deal with numerical values and recognize meaning in them. In order for them to be able to understand and process words, they first have to be translated (tokenized). There are many different types of tokenization (e.g. WordPiece, BPE), but the basic principle always remains to break down a larger text with words and characters into numerical components.
The Tokenizer class (🤗 Tokenizer)
“A Tokenizer works as a pipeline, it processes some raw text as input and outputs an Encoding.” (🤗 Tokenizer). The steps of the pipeline are:
- Normalizer: normalizes the text e.g. lowercase, or replace characters
- Pretokenizer: initial word splits e.g. on whitespace. The result is a list of tuples with the word and its position within the text
- Model: The actual tokenization algorithm such as WordPiece. Depending on the algorithm and training corpera used, this will further split the words into smaller fractions
- PostProcessor: Adds anything relevant to the encoded sequence such as special tokens ([CLS]), which might be needed for language model training
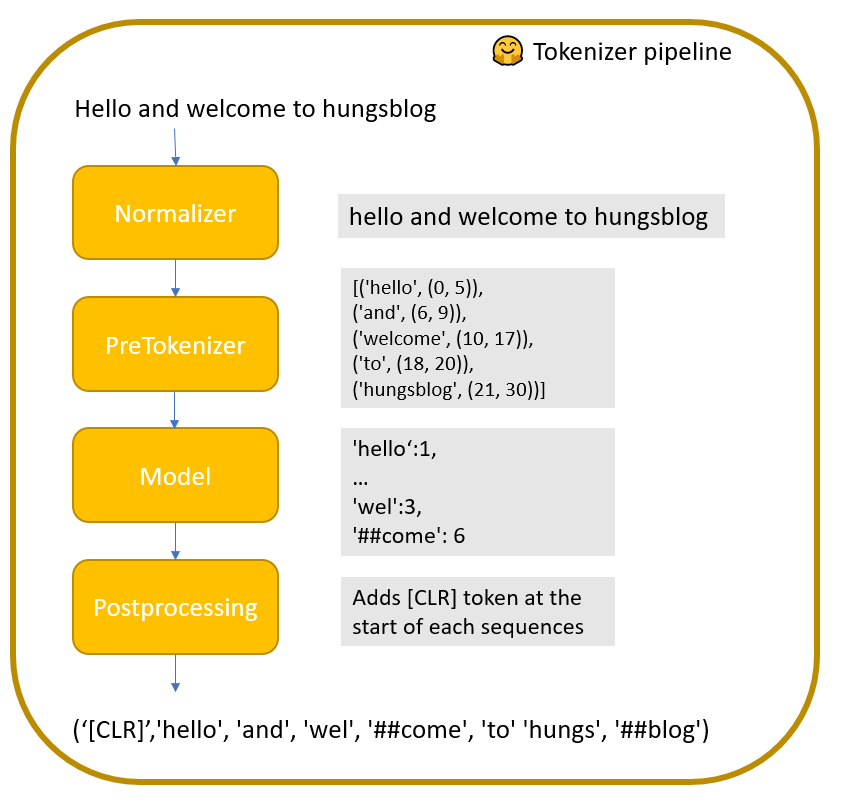
You can configure your own Tokenizer pipeline and train a model on your corpera. Depending on your training data, the model will output different tokens. A good tutorial to build a tokenizer from scratch can be found in this google colab notebook (not mine). This allows you to set the vocab_size or add additional special_tokens.
You can save this predefined pipeline along with the trained tokens as a json file.
The PreTrainedTokenizer class (🤗 Transformers)
The PreTrainedTokenizer class is more of a wrapper around an existing Tokenizer model and provides additional functionality to be utilized by other components of the 🤗 Transformers framework. For example the DataCollatorForLanguageModeling will call the tokenizer’s get_special_token() function to retrieves a mask which denotes at which position a special tokens occurs.
Additionally, the PreTrainedTokenizer class can also be preconfigured for your needs. If you want to train e.g. a Bert Model, you want to specify some special tokens, which the model can interpret and use as markers, such as [MASK], [CLS], etc. For this purpose you can set those special tokens using the property atttributes of the tokenizer.
Saving the PreTrainedTokenizer will result into a folder with three files.
- A tokenizer.json, which is the same as the output json when saving the Tokenizer as mentioned above,
- A special_tokens_map.json, which contains the mapping of the special tokens as configured, and is needed to be retrieved by e.g. the
get_special_tokens_mask() - another configuration file.
How to add custom special_tokens to a PreTrainedTokenizer
To add additional custom special tokens (for whatever reason), you can assign a list of your custom special tokens to the additional_special_tokens property attribute of your PreTrainedTokenizer object.
tokenizer.additional_special_tokens=['list','of','custom','special','attributes']
Once configured and saved, you will see this mapping included in the special_tokens_map.json file, created when saving the PreTrainedTokenizer. This is important, since now the to be trained language model has information on special tokens and can e.g. disregard those, when creating a mask for the masked language modeling task.
If this helped you or if you like to provide some feedback, feel free to leave a comment 🙂
Can you please show me how to add mask token in the pretrainedFasttokenizer? It would be really helpful.
Hey arnab,
sorry for answering so late and you might have solved your problem already.
I am not 100% certain, what you mean, but i assume, you want to assign a specific token to the mask_token property of the PretrainedTokenizerFast. To do so simply assign it:
t = PreTrainedTokenizerFast(tokenizer_object=trained_tokenizer)
t.mask_token = '[MASK]'
Best Regards
Hung