In German, we encounter special characters known as Umlaute, including ä, ü, ö. If the configuration is not correctly set, encoding these symbols may result in information loss. Let’s explore a practical example where such a misconfiguration led to a failure in a Spark pipeline.
The System
I am currently involved with a system outlined as shown in the image below. Airflow orchestrates an ETL job that Spark executes. In this process, I pass a SQL statement to Spark as an argument. The driver then receives this argument and executes the code within its application. However, due to improper encoding, there the pipeline breaks.
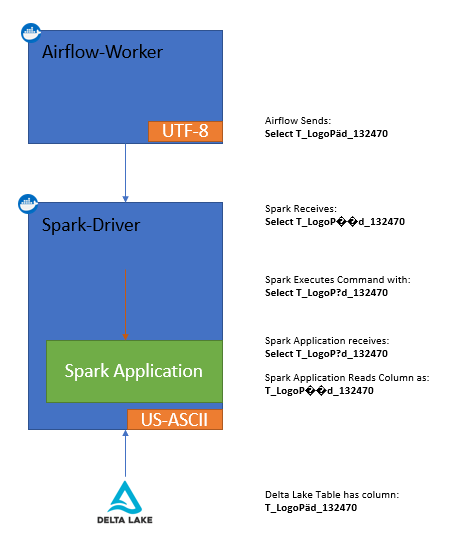

Troubleshooting & Fixing
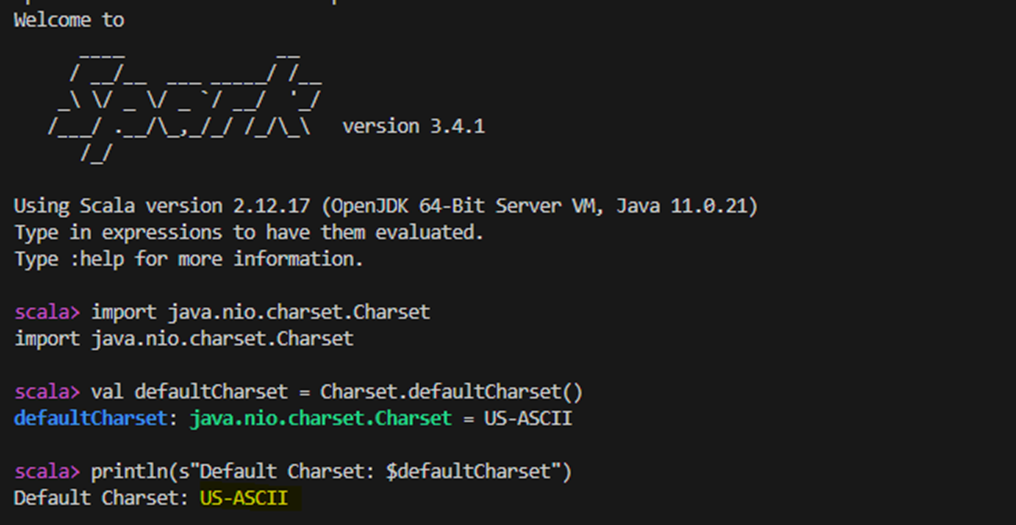
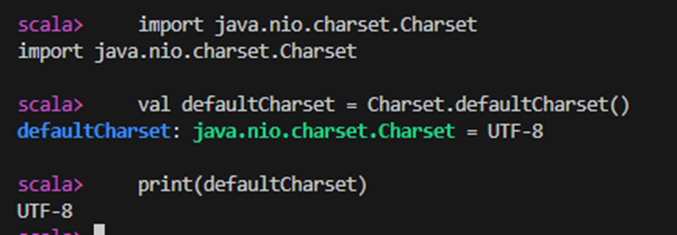
When I access my Spark container and run the spark-shell, then output the charset, it indeed reports: US-ASCII. This indicates that the default character encoding might be contributing to some kind of information loss, especially in this case, where the SQL statements contains characters not supported by US-ASCII.
import java.nio.charset.Charset
val defaultCharset = Charset.defaultCharset()
print(defaultCharset)
So i followed the advice stackoverflow (and chatgpt) which suggest to configure the local encoding and I ran:
apt-get install -y locales && rm -rf /var/lib/apt/lists/* && locale-gen en_US.UTF-8
export LANGUAGE="en_US:en„
export LANG="en_US.UTF-8“
export LC_ALL="en_US.UTF-8"
However running the last export gave me a warning:
bash: warning: setlocale: LC_ALL: cannot change locale (en_US.UTF-8)

Upon rechecking in the spark-shell, it was evident that the configuration changes had no effect. Additionally, the process triggered some warnings.

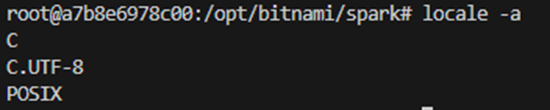
So I run a query for the error message and the answer was, that the locals we are “requesting have not actually been compiled” (stackexchange). Also pointed out in this comment. And indeed running locale -a did not show en_US.UTF-8.
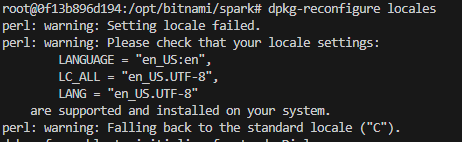
To compile it we can run dpkg-reconfigure locales but that would make us go through an interactive shell. It also prompts us that the en_US.UTF-8 encoding we configured might not be installed on the system yet.
Since we eventually want to implement it in a Dockerfile, we want something more convinient. Funny enough, I return to my very first stackoverflow answer which gives a nice sed command: sed -i '/en_US.UTF-8/s/^# //g' /etc/locale.gen && locale-gen
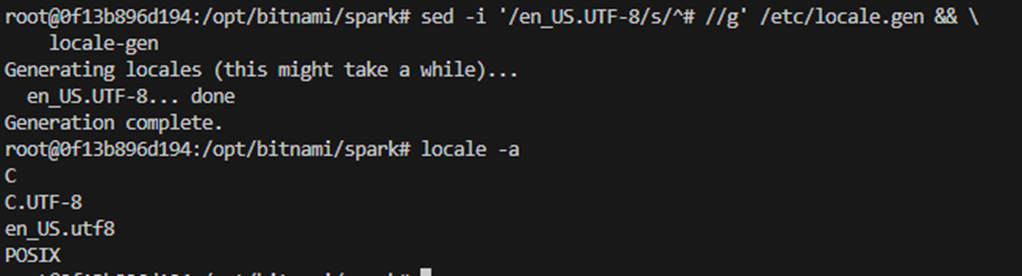
Lastly we set the enviroment variables, and that did change the JVM charset, even without a reboot.
Final Dockerfile snippet
Now we want to implement all our findings in the Dockerfile. The resulting snippet looks like this:
RUN apt-get install -y locales && rm -rf /var/lib/apt/lists/* \
&& sed -i '/en_US.UTF-8/s/^# //g' /etc/locale.gen && \
locale-gen
ENV LANG en_US.UTF-8
ENV LANGUAGE en_US:en
ENV LC_ALL en_US.UTF-8
And there we go, we succesfully installed and configured en_US.UTF-8 on our Spark image.