Observation
A deployed pod is stuck in pending status. A describe pod gives the following warning:
Warning FailedScheduling [..] 0/3 nodes are available: 3 node(s) had no available volume zone.

What happened
We already had a PVC (PVC_A), which we wanted to backup. We created another PVC (PVC_dummy) and attempted to mount both PVCs in one pod.
Unfortunetely the deployed background PV for those PVCs were deployed on different availability domains (AD). This can be observed by running describe PV.
Apparently a deployed pod in one zone, cannot access a storage in another zone, which is exactly what happened here. (Normally when creating a pod Kubernetes would make sure, that it will be placed in the same zone as the volume. See storage access for zones).
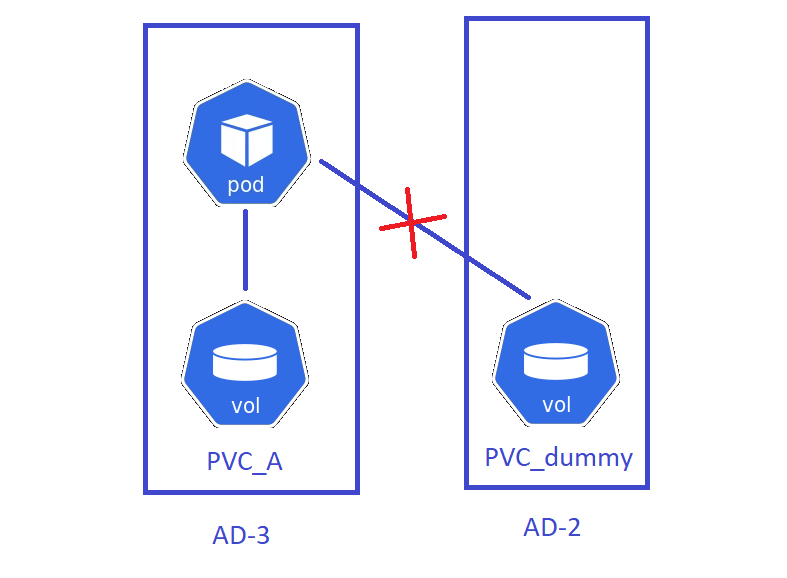
Resolution
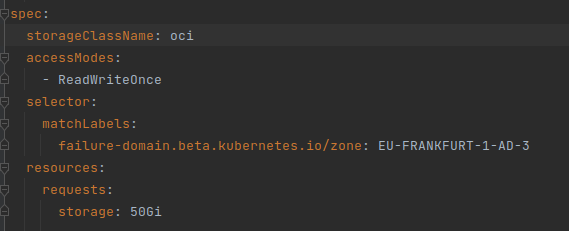
To circumvent this, we can deploy the additional PVC in the same zone as the previous PVC by utilizing matching labels, which Kubernetes assigns to each node at startup (see node-behavior)
Alternatively when deploying the new PVC PVC_dummy you could also select a storageclass which is set to WaitForFirstConsumer (see volume binding mode), “which will delay the binding and provisioning of a PersistentVolume until a Pod using the PersistentVolumeClaim is created“. This will ensure, that the pod will be deployed to the right AD with the already existing PVC and then trigger the provisioning of the PV for the new PVC likewise in the right AD.